
Downloading
The downloading stage checks data sources for changes in structure or format. Validation ensures that the downloaded data matches expectations.

.png)
Knowledge graph
.png)

Creating a knowledge graph involves two important parts: the user interface and the data storage system.
ETL processes are used to convert and combine data efficiently. The data is then prepared for easy access. Monitoring and notifications are carefully managed to make sure the data flows smoothly.
The knowledge graph can do more with predictive models. These models use advanced techniques to do different tasks, like checking toxicity or recommending similar drugs. These tasks make the knowledge graph more impactful and give researchers more useful information.
The knowledge graph is also useful for searching. It helps users find specific information and important details. This information can be used to make smart choices, like adjusting experiments or improving drug production using past data.
One critical aspect of building and maintaining a knowledge graph is data licensing.
Many sources provide data under various licenses, and it's crucial to understand the licensing terms and ensure that the data is available for use.
Moreover, maintaining data licenses is not a one-time task. It requires regular reviews because sources and their licenses can change over time. This ongoing process ensures that the knowledge graph remains compliant with the latest licensing terms.
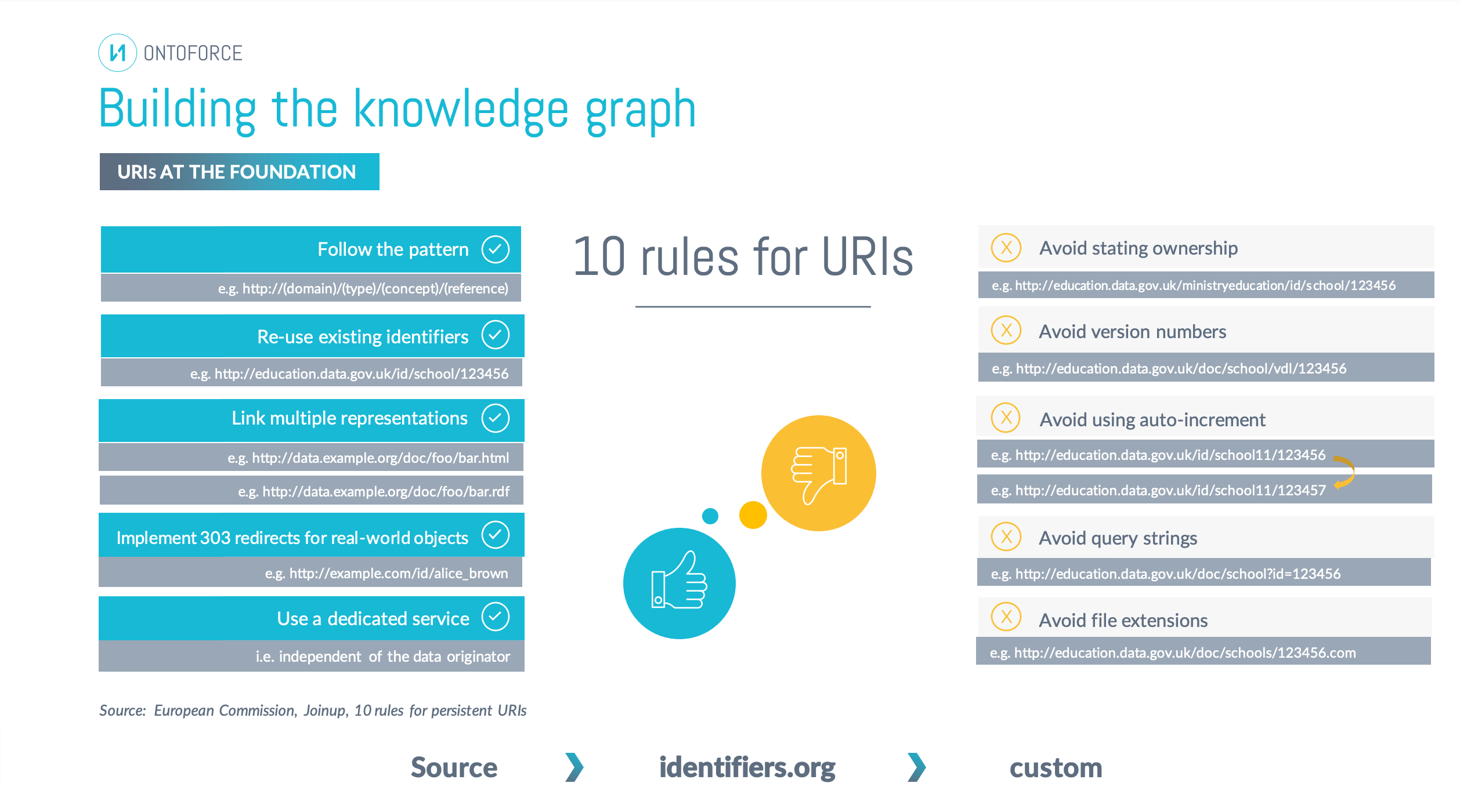
After integrating data sources into the knowledge graph, the first step is to create unique URIs for entities.
The choice of URI structure depends on various factors, including the presence of source-specific UI schemas.


ONTOFORCE enables life science companies to unlock hidden insights from data.
With DISQOVER, built on knowledge graph technology, we support life sciences and pharmaceutical companies with innovative data management and visualization.
![]()
![]()



.png)